Studiedata, niet te verwarren met data over studies, is een verzamelnaam voor een breed scala aan gestructureerde gegevens die binnen onderwijsinstellingen benut kunnen worden voor het verbeteren van het onderwijs. Daarbij onderscheiden we drie richtingen voor verbetering: de kwaliteit van onderwijs, de effectiviteit van het onderwijs en de efficiëntie van het onderwijs.
Data over de context en content van het onderwijs
Studiedata ontstaan door alle vormen van onderwijs of processen die het onderwijs mogelijk maken. Het gaat dan ook alle ‘actoren’ in dat onderwijs aan: studenten met inschrijvingen en studieresultaten, docenten en hun vakken, opleidingsdirecteuren en de kwaliteit van opleidingen, studieadviseurs en de studievoortgang van hun studenten, ondersteuners in het onderwijs en data over deelname aan onderwijs, beleidsmakers en inzichten die voor de ontwikkeling of evaluatie van onderwijsbeleid nuttig zijn, bestuurders en instellingsdata, en niet te vergeten onderzoekers naar onderwijs en studiedata.
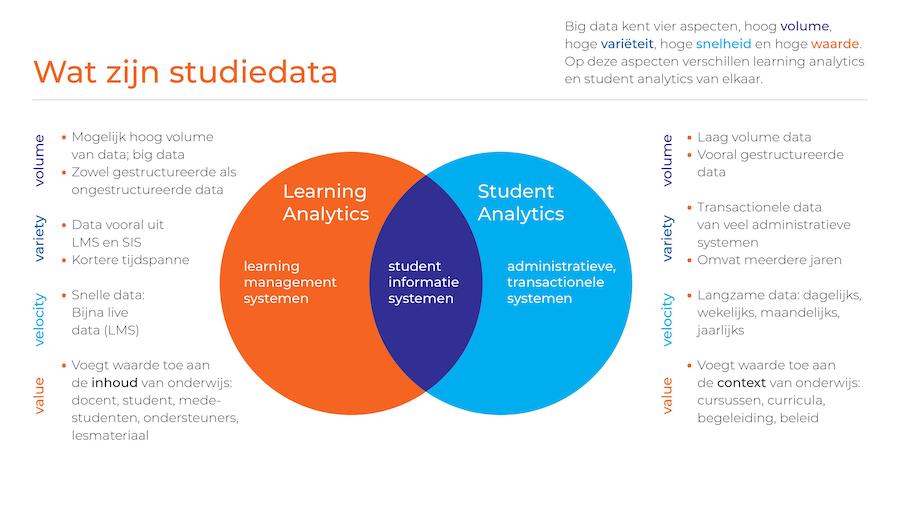
Welke data hebben we zoal tot onze beschikking om deze mogelijkheden voor verbetering te benutten? De meeste studiedata zijn vastgelegd in informatiesystemen voor onder andere het geven van onderwijs, de administratie van inschrijvingen en studieresultaten, kwaliteitszorg en afnemen van toetsen. Je kan data indelen naar toepassingsgebied, de content of context van het onderwijs. Daarbij verschillen die gebieden op een aantal big data aspecten (de 4 V’s): volume, variety, velocity en value. Big data kenmerkt zich door een hoog volume aan data, hoge variëteit aan variabelen, hoge omloopsnelheid van data en veel waarde die kan ontstaan uit analyses. Een voorbeeld is analyses van aandelen op de beurs of berichten op social media. Of studiedata ook big data zijn is nog maar de vraag als we naar deze aspecten kijken. We zullen zien dat studiedata uit de content van het onderwijs meer op big data lijkt, dan dat voor het studiedata uit de context van het onderwijs.
- Onderwijssystemen gaan over de content van onderwijs en toetsing, ook wel primaire proces genoemd. Denk hierbij aan Leermanagement Systemen (LMS), feedback systemen, systemen om onderwijs te toetsen, plagiaattools, enzovoort. Deze studiedata is voor en deel goed gestructureerd, maar kan ook ongestructureerde data bevatten en kan een flink volume aannemen. De variëteit aan data is redelijk beperkt en vaak van belang binnen korte tijdsspanne, bijvoorbeeld een lesperiode. Omdat deze data vaak snel gebruikt moet worden in het onderwijs zelf is deze het liefst real-time beschikbaar. Deze studiedata voegt de meeste waarde toe aan docenten, studenten en medestudenten, ondersteuners, en het lesmateriaal dat zij met elkaar gebruiken of ontwikkelen. Analyses van dit type data valt onder de noemer Learning Analytics.
- Denk bij administratieve systemen aan informatiesystemen over de context van het onderwijs, ook wel ondersteunende of secundaire processen genoemd. Bijvoorbeeld een Student Informatiesysteem (SIS) voor het vastleggen van inschrijvingen en studieresultaten, Studielink voor de registratie van aanmeldingen en gegevens over vooropleiding, systemen voor matching met aankomende studenten, Customer Relationship Management (CRM) systemen voor registratie van deelname aan open dagen, meeloopdagen, proefstuderen, introductiedagen, systemen voor roostering, studiegidsen, uitkomsten van de Nationale Studenten Enquête en zo voort. Deze studiedata is over het algemeen goed gestructureerd en – naar verhouding met onderwijsdata – bescheiden in omvang. Ze komen uit een heel scala aan informatiesystemen die administratieve processen ondersteunen (transacties) en bevatten veel historische gegevens die vaak gebonden zijn aan bewaartermijnen. De snelheid waarmee dit soort data bij voorkeur geanalyseerd wordt is vaak lager: soms dagelijks, zoals aanmeldingen per opleidingen, maar vaak volstaat een update een keer per week (voor studieresultaten), een keer per maand (voor inschrijvingen) of zelfs een keer per jaar (voor opleidingsgegevens). Deze studiedata voegt de meeste waarde toe aan beleidsmakers, opleidingsdirecteuren, bestuurders, studentbegeleiders met inzichten in cursussen, curricula, begeleiding en beleidsvraagstukken. Analyses naar dit type data valt onder de noemer Student Analytics.
Aanvullende studiedata kunnen verzameld worden vanwege wetenschappelijk onderzoek, zoals een onderzoeksenquête of een logboekverslag. Een vrij nieuwe vorm van studiedata kan voortkomen uit het gebruik van devices in onderwijsgebouwen zoals het wifi-gebruik, wat bijvoorbeeld iets kan zeggen over de deelname aan onderwijs, het gebruik van onderwijslocaties of de bezetting van publieke ruimtes in onderwijsgebouwen.
Inzichten in onderwijs op verschillende niveaus van aggregatie
Door studiedata te verzamelen, te combineren en te aggregeren kunnen onderwijsinstellingen op allerlei niveaus analyses plegen voor verschillende doeleinden op dat niveau.
 Laten we als voorbeeld data nemen over de studievoortgang van studenten per vak.
Laten we als voorbeeld data nemen over de studievoortgang van studenten per vak.
Een analyse van deze gegevens kan op opleidingsniveau helpen bij het beantwoorden van vragen over de studeerbaarheid van een onderwijsprogramma: Welke vakken scoren naar verhouding het minst? Speelt dit voor alle studenten of is er een verband met hun achtergrond? Was dit ieder jaar het geval, of zien we daar nog bijzondere patronen in?
In combinatie met data van dezelfde opleidingen bij andere onderwijsinstellingen kan dezelfde data op landelijk niveau dienen voor benchmarks op bijvoorbeeld het succes van afgestudeerden. Wat is het succes van studenten per opleiding? Zijn er verschillen tussen opleidingen binnen of buiten de randstad? Wat zijn hier meerjarige trends?
Op persoonlijk niveau kan dezelfde data een docent helpen bij het verbeteren van het onderwijs, of een student helpen met een gericht advies. Hoe scoor ik als student vergeleken met andere studenten? Zijn mijn scores hoger of lager dan het gemiddelde op mijn andere vakken? Wat is de mogelijke impact van dit vak op mijn verdere studieverloop?
Afhankelijk van de toepassing en het soort data gelden andere mogelijkheden en verplichtingen vanuit de AVG. Het is daarbij van belang dat een onderwijsinstelling waarborgt dat in principe zo min mogelijk data wordt verzameld als nodig, de voordelen van het gebruik zo groot mogelijk zijn en aansluiten bij de ethische principes van een instelling, en er voldoende waarborgen zijn om het risico op eventuele nadelige effecten te minimaliseren.
Studiedata doorlopen een proces om bruikbare studiedata te worden
Het verzamelen en verwerken van data doorloopt meerdere stappen om waardevolle data te worden. In dat proces kunnen nieuwe data gekoppeld en ontwikkeld worden.
 Een data ‘pijplijn’ of waardeketen kan er als volgt uitzien.
Een data ‘pijplijn’ of waardeketen kan er als volgt uitzien.
- De ontwikkeling van studiedata start met het verzamelen van ruwe data uit of meerdere gegevens en die technisch correct te maken. In deze stap krijgen variabelen bij voorkeur een begrijpelijk naam.
- In de volgende stap maken we consistente data: krijgen variabelen van dezelfde soort ook hetzelfde formaat. Een datumveld wordt bijvoorbeeld overal omgezet naar ‘dd-mm-yyyy’ c.q. 12-01-2021. Ook is dit de stap waarin keuzes worden gemaakt in ontbrekende data. Deze zijn soms goed op te vullen. Ook data die ontbreekt is informatief. Als een student bijvoorbeeld niet voorkomt in de open dagen dataset, dan is het zeer aannemelijk dat hij/zij niet op een open dag is geweest.
- Hierna maken we de overgang naar verrijkte data. Op basis van de bestaande data kan nieuwe studiedata afgeleid worden of gekoppeld worden met andere datasets. Als we bijvoorbeeld weten wanneer iemand zich voor een opleiding heeft aangemeld, dan kunnen we ook berekenen hoeveel dagen dit was voor 1 september.
- In de statistische resultaten stap onderzoeken we de verbanden binnen de data. Dit is het moment waarop we zaken onderzoeken als aantallen, het gemiddelde, de mediaan, standaarddeviatie, correlatie en zo voort. We ontdekken bijvoorbeeld dat de meeste studenten zich aanmelden één dag voor de deadline en dat de kans om uit te vallen hoger is bij studenten die zich na de deadline hebben aangemeld. Als we daar de deadlines van de verschillende opleidingen mee combineren geeft dat weer meer inzicht in logische verschillen voor opleidingen met of zonder een selectieprocedure.
- Tot slot zetten we de kennis om naar actiegerichte inzichten in de vorm van dashboards, onderzoeksrapporten en adviesgesprekken. Mogelijke vragen die – in lijn met het voorbeeld tot nu toe – hierin beantwoord worden zijn: Hoe komt het studenten zich later aanmelden; wat zijn de achterliggende reden? Dan blijkt bijvoorbeeld dat dit vaker herkiezers zijn die om verschillende redenen zich later aanmelden: uitgeloot bij een andere studie, een herexamen op het vwo, een negatief BSA elders. Vaker zijn zij dus wat ouder, oriënteren zich anders op hun studie omdat de open dagen al voorbij zijn, ze hebben misschien al een keer een introductie gevolgd. Dan komen mogelijkheden voor interventies in zicht. Is het mogelijk om de online communicatie over opleidingen zo aan te passen dat studenten die zich hebben aangemeld na de deadline beter begrijpen hoe zij zich alsnog goed kunnen voorbereiden op hun studie? Welke rol zouden matching en introductie hierin kunnen spelen?