Op 16 december vond het webinar Broodje Statistiek van de zone Studiedata plaats. In dit webinar over het Statistisch Handboek Studiedata (SHS) kwamen niet alleen de updates van het handboek aan bod, maar gaf Elian Griffioen ook een uitleg van regressiemodellen en bespraken we de toetsmatrix aan de hand van een casus. In dit verslag lees je wat er tijdens het webinar is besproken.
Aanleiding voor het webinar was dat de eerste van drie toetsmatrices gevuld is! Elke tegel in het SHS verwijst nu door naar een pagina met uitleg over die toets aan de hand van een case uit hoger onderwijs. Ook vind je er de code in R en Python. Nu zijn we bezig met het uitwerken van de tweede matrix. Hierin staan straks statistische technieken die geschikt zijn om een analyse te doen met meerdere onafhankelijke variabelen.
Soorten analyses
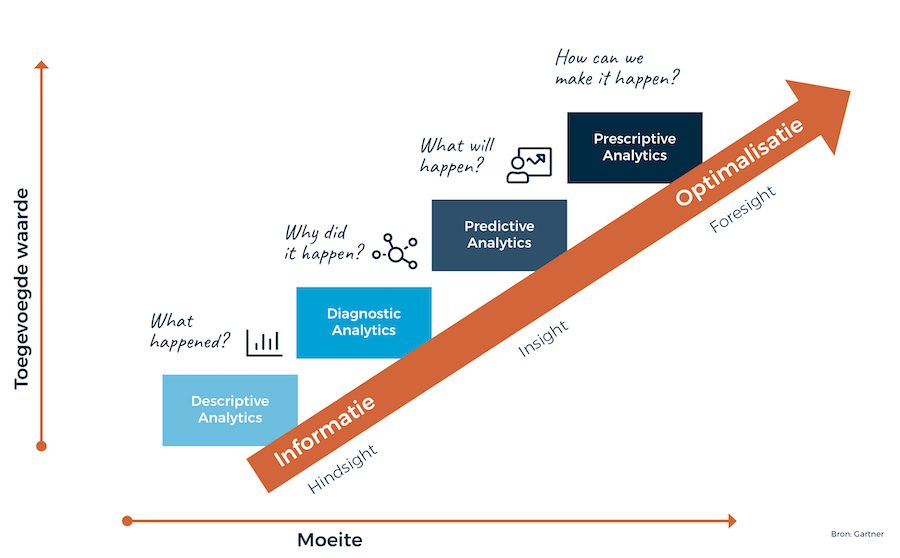 Het model van Gartner schetst de verschillende soorten van data-analyses. Je kunt analyses inzetten om iets te omschrijven (descriptive), om het te verklaren (diagnostic), te voorspellen (predictive) of voor te schrijven (prescriptive). De eerste twee toetsmatrices bevatten statistische technieken die gebruikt worden om relaties tussen variabelen te toetsen. Deze toetsmatrices zijn dus in te delen onder diagnostic analytics. De derde toetsmatrix zal in het teken staan van machine learningtechnieken. Deze worden gebruikt om prognoses te genereren, wat een voorbeeld is van predictive analytics. Regressiemodellen kunnen gebruikt worden om relaties tussen variabelen statistisch te toetsen, maar ook om een voorspelling van een variabele te maken. Daarom vallen regressiemodellen onder zowel diagnostic als predictive analytics.
Het model van Gartner schetst de verschillende soorten van data-analyses. Je kunt analyses inzetten om iets te omschrijven (descriptive), om het te verklaren (diagnostic), te voorspellen (predictive) of voor te schrijven (prescriptive). De eerste twee toetsmatrices bevatten statistische technieken die gebruikt worden om relaties tussen variabelen te toetsen. Deze toetsmatrices zijn dus in te delen onder diagnostic analytics. De derde toetsmatrix zal in het teken staan van machine learningtechnieken. Deze worden gebruikt om prognoses te genereren, wat een voorbeeld is van predictive analytics. Regressiemodellen kunnen gebruikt worden om relaties tussen variabelen statistisch te toetsen, maar ook om een voorspelling van een variabele te maken. Daarom vallen regressiemodellen onder zowel diagnostic als predictive analytics.
Download hier de presentatie van het webinar.
Slides 9 t/m 16 geven een uitleg van regressie.
FAQ
Aan het eind van de presentatie was er ruimte voor vragen. En die waren er genoeg!
Hoe hangen regressiemodellen samen met het handboek?
In de tweede toetsmatrix van het Statistisch Handboek zijn regressie-analyses te vinden. Afhankelijk van het meetniveau van de afhankelijke variabele en een aantal andere karakteristieken van de data kies je de juiste statistische methode. Vervolgens wordt in de toetspagina uitgelegd hoe de regressie-analyse werkt, hoe je het uitvoert en hoe je het interpreteert. Al deze stappen worden in de toetspagina ook uitgevoerd aan de hand van een casus uit het hoger onderwijs met behulp van de programmeertalen R en Python.
Hoe maak je de keuze tussen een lineaire of logistische regressie?
Deze keuze hangt af van het meetniveau van de afhankelijke variabele. Bij multipele lineaire regressie is het meetniveau van de afhankelijke variabele continu; bij logistische regressie is het meetniveau van de afhankelijke variabele binair. De toetsmatrix licht deze keuze toe.
Heeft regressie nog nut gezien dat wat mogelijk is met machine learning?
Hier speelt de kwestie van definities een rol. Regressie is een specifieke techniek en machine learning is een verzamelnaam van technieken die (onder andere) gebruikt worden om prognoses te maken. Regressie is een techniek die het mogelijk maakt om voorspellingen te maken, dus kan gezien worden als een onderdeel van machine learning. Regressie is nog steeds een gebruikte techniek binnen machine learning. Het voordeel van regressie is namelijk dat je kan verklaren op basis waarvan een bepaalde voorspelling gedaan wordt. Het is een white box model. Er zijn ook machine learning technieken waar dit lastiger is, de zogenaamde black box modellen. Vanuit betrokkenen kan er een wens zijn om een white box model te hebben voor de uitlegbaarheid van voorspelling, in dat geval is regressie een handige, transparante techniek om voorspellingen te maken.
Hoe weet ik of ik de eerste of tweede toetsmatrix moet gebruiken?
Het officiële onderscheid tussen toetsmatrix I en II is het aantal onafhankelijke variabelen. Toetsmatrix I wordt gebruikt wanneer er één onafhankelijke variabele is, toetsmatrix II wanneer er twee of meer onafhankelijke variabelen zijn. Het aantal onafhankelijke variabelen is een methodologische keuze en hangt af van de onderzoeksvraag. De analyses in de tweede toetsmatrix worden gebruikt wanneer er meerdere variabelen relevant zijn, dit zorgt er voor dat de analyse wat breder en genuanceerder is.
Ervaringen en suggesties van deelnemers
We vroegen de deelnemers een aantal vragen te beantwoorden over hoe zij het SHS kenden en gebruikten.
- 70% van de deelnemers heeft het SHS bezocht sinds lancering (februari 2020), maar ook 70% van de deelnemers heeft het nog niet toegepast in het eigen werk;
- 100% heeft de wens om het handboek meer toe te gaan passen;
- 90% zou ermee geholpen zijn om vaker online samen te komen om het handboek te bespreken of te oefenen met het toepassen in de praktijk.
Daarnaast vroegen we deelnemers wat zij nodig hadden om het SHS te kunnen gebruiken:
- casussen met surveydata;
- bekende instinkers met betrekking tot aannames publiceren;
- een FAQ opbouwen;
- webinar organiseren op instellingsniveau;
- casusbibliotheek opbouwen.